Glusterfs逻辑卷创建与使用
volume是brick的组合,并且大部分glusterfs文件系统的操作都在volume上。
glusterfs支持4种基本卷,并可以根据需求对4种基本卷进行组合形成多种扩展卷(得益于glusterfs的模块化堆栈架构设计)。
以下主要展示各类型逻辑卷的功能性,未对性能做测试验证。
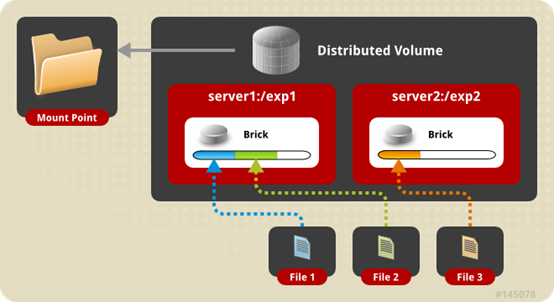
分布式卷
分布式卷(Distributed Glusterfs Volume,又称DHT),glusterfs创建volume不指定卷类型时,默认即分布式卷,特点如下:
- 根据hash算法,将多个文件分布到卷中的多个brick server上,类似(不是)raid0,但文件无分片;
- 方便扩展空间,但无冗余保护;
- 由于使用本地文件系统进行存储(brick server 的本地文件系统),存取效率不高;
- 受限于本地文件系统对单文件容量的限制,支持超大型文件系统有问题。
创建存储目录(optional)
1 | # 在brick server节点创建存储目录,即brick所在; |
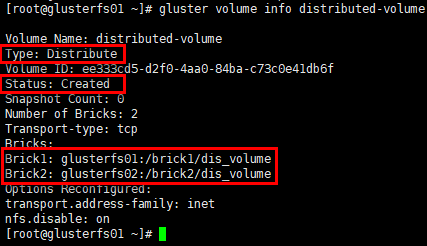
创建分布式卷
1 | # 命令:gluster volume create NEW-VOLNAME [transport [tcp | rdma | tcp,rdma]] NEW-BRICK... |

卷信息/状态
1 | # 命令”gluster volume list”可列出已创建的卷; |
1 | # 查看卷状态; |
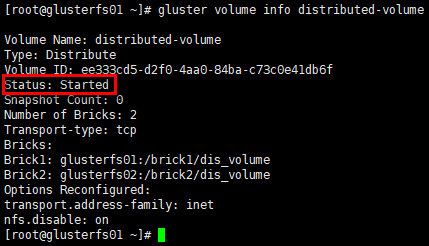
启动卷
1 | [root@glusterfs01 ~]# gluster volume start distributed-volume |

1 | # 再次查看卷信息,状态变为"Started" |
client挂载
1 | # 在客户端创建挂载目录 |
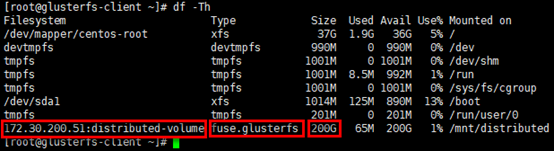
查看挂载情况
1 | # 通过“df -Th”命令可查看被挂载的volume,被挂载的文件系统,已经挂载卷的容量是2个brick容量之和 |
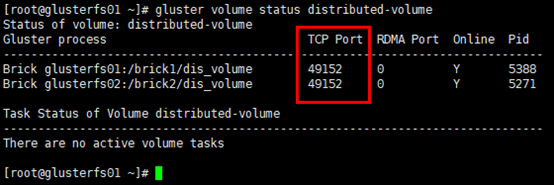
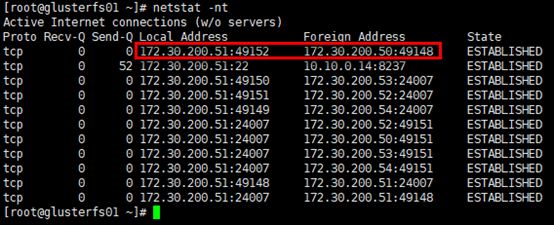
查看brick的监听端口
1 | # server节点上每启动1个brick,即启动1个brick服务,具备相应的服务监听端口,起始端口号是tcp49152 |

1 | # 另外,client连接的即brick服务的监听端口 |
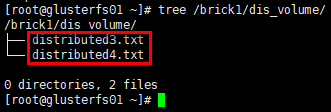
存储测试
1 | # 在client的挂载目录下创建若干文件 |
1 | # glusterfs02节点 |
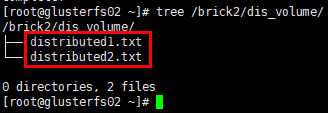
结论:分布式卷将多个文件分布存储在多个brick server,但并无副本。
条带卷(Deprecated)
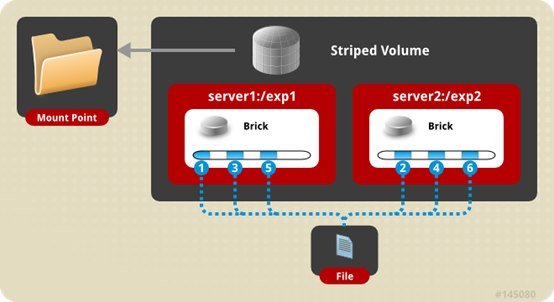
条带卷(Striped Glusterfs Volume),特点如下:
- 每个文件被分片成等同于brick数量的chunks,然后以round robin的方式将每个chunk存储到1个brick,相当于raid0;
- 单一超大容量文件可被分片,不受brick server本地文件系统的限制;
- 文件分片后,并发粒度是chunks,分布式读写性能较高,但分片随机读写可能会导致硬盘iops较高;
- 无冗余,1个server节点故障会导致所有数据丢失。
创建条带卷
1 | # 命令:gluster volume create NEW-VOLNAME [stripe COUNT] [transport [tcp | dma | tcp,rdma]] NEW-BRICK... |

启动卷
1 | [root@glusterfs01 ~]# gluster volume start stripe-volume |

client挂载
1 | [root@glusterfs-client ~]# mkdir /mnt/stripe |
查看挂载情况
1 | # 已挂载卷的容量是3个brick容量之和 |
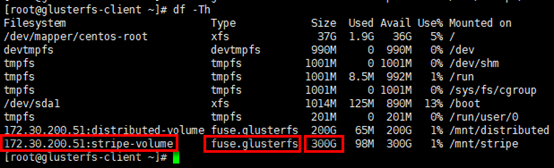
存储测试
1 | # 在client的挂载目录下创建若干文件 |
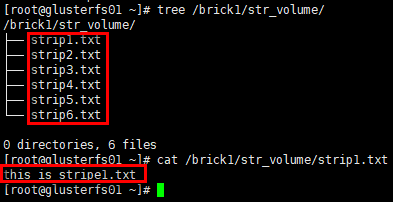
1 | # glusterfs02节点 |
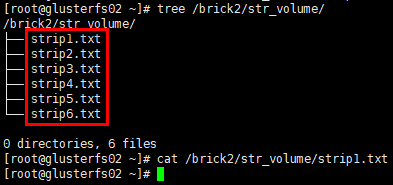
1 | # glusterfs03节点 |
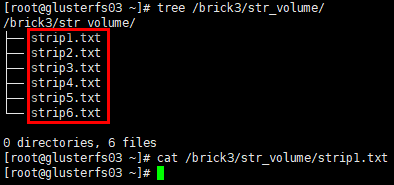
结论:条带卷将1个文件分片存储在多个brick server,但并无副本。
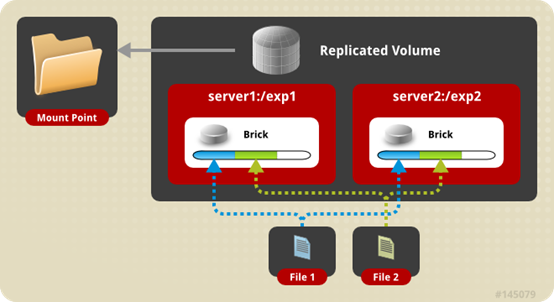
复制卷
复制卷(Replicated Glusterfs Volume,又称AFR(Auto File Replication)),特点如下:
- 每个文件同步复制镜像到多个brick,相当于文件级raid1;
- 副本数量通常设置为2或3,设置的副本数量需要是brick数量(至少为2)的倍数(如2台brick server,可设置副本数为2/4/6/…;如3台brick server,可设置副本数为3/6/9/…;依次类推),且每个brick的容量相等;
- 读性能提升,写性能下降,因为glusterfs的复制是同步事务操作,即写文件时,先把这个文件锁住,然后同时写两个或多个副本,写完后解锁,操作结束(ceph采用异步写副本,即写到一个主OSD便返回,这个OSD再通过内部网络异步写到其余OSD);
- 通常与分布式卷或条带卷组合使用,解决前两者的冗余问题;
- 提升数据可靠性,但磁盘利用率低;
- 副本数设置为2时,可能会有脑裂(Split-brain)的风险(风险提示,但可配置),主要因在两个副本不一致时,无法仲裁以哪个副本为准,解决方案是加入仲裁或者设置3副本。
创建复制卷
1 | # 命令:gluster volume create NEW-VOLNAME [replica COUNT] [transport [tcp | rdma | tcp,rdma]] NEW-BRICK... |

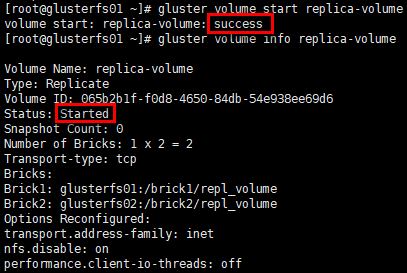
启动卷
1 | [root@glusterfs01 ~]# gluster volume start replica-volume |
client挂载
1 | [root@glusterfs-client ~]# mkdir /mnt/replica |
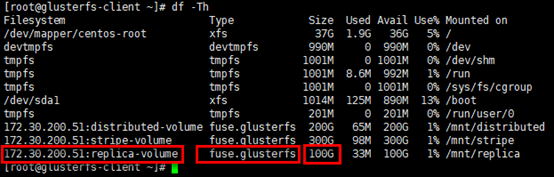
查看挂载情况
1 | # 已挂载卷的容量是1个brick的容量 |
存储测试
1 | # 在client的挂载目录下创建若干文件 |
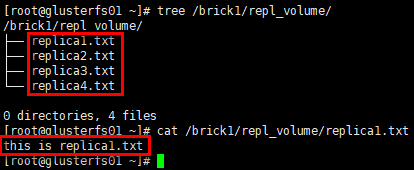
1 | # glusterfs02节点 |
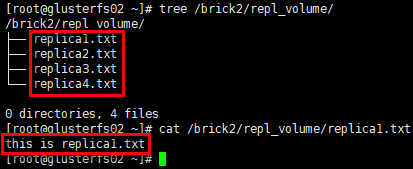
结论:复制卷将1个文件同步镜像到多个brick server,数据有冗余备份。
AFR恢复原理
数据恢复只针对复制卷,AFR数据修复主要涉及三个方面:ENTRY,META,DATA。
记录描述副本状态的称之为ChangeLog,记录在每个副本文件扩展属性里,读入内存后以矩阵形式判断是否需要修复以及要以哪个副本为Source进行修复;初始值以及正常值为0(注:ENTRY和META,DATA分布对应着一个数值)。
以冗余度为2,即含有2个副本A和B的DATA修复为例,write的步骤分解为:
- 下发Write操作;
- 加锁Lock;
- 向A,B副本的ChangeLog分别加1,记录到各副本的扩展属性中;
- 对A,B副本进行写操作;
- 若副本写成功则ChangeLog减1,若该副本写失败则ChangLog值不变,记录到各个副本的扩展属性中;
- 解锁UnLock;
- 向上层返回,只要有一个副本写成功就返回成功。
上述操作在AFR中是完整的一个transaction动作,根据两个副本记录的ChangeLog的数值确定了副本的几种状态:
- WISE:智慧的,即该副本的ChangeLog中对应的值是0,而另一副本对应的数值大于0;
- INNOCENT:无辜的,即两副本的ChangeLog对应的值都是0;
- FOOL:愚蠢的,即该副本的ChangeLog对应的值大于是0,而另一副本对应的数值是0;
- IGNORANT,忽略的,即该副本的ChangeLog丢失。
恢复分以下场景:
1个节点changelog状态为WISE,其余节点为FOOL或其他非WISE状态,以WISE节点去恢复其他节点;
所有节点是IGNORANT状态,手动触发heal,通过命令以UID最小的文件作为source,去恢复大小为0的其他文件;
多个状态是WISE时,即出现脑裂状态,脑裂的文件通常读不出来,报”Input/Output error”,可查看日志/var/log/glusterfs/glustershd.log。
脑裂原理及解决方案:[https://docs.gluster.org/en/latest/Administrator%20Guide/Split%20brain%20and%20ways%20to%20deal%20with%20it/](https://docs.gluster.org/en/latest/Administrator Guide/Split brain and ways to deal with it/)
1 | # 通过命令查看副本文件的扩展属性:getfattr -m . -d -e hex [filename] |

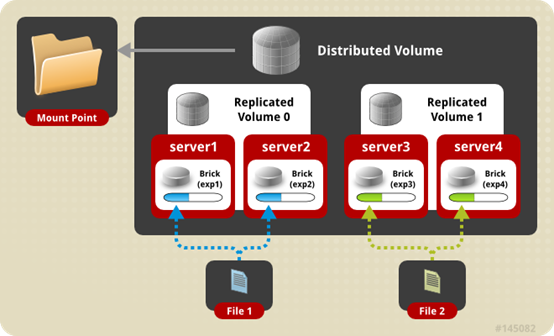
分布式复制卷
分布式复制卷(Distributed Replicated Glusterfs Volume),是分布式卷与复制卷的组合,兼具两者的功能,特点如下:
- 若干brick组成1个复制卷,另外若干brick组成其他复制卷;单个文件在复制卷内数据保持副本,不同文件在不同复制卷之间进行哈希分布;即分布式卷跨复制卷集(replicated sets );
- brick server数量是副本数量的倍数,且>=2倍,即最少需要4台brick server,同时组建复制卷集的brick容量相等。
创建分布式复制卷
1 | # 命令:gluster volume create NEW-VOLNAME [replica COUNT] [transport [tcp | rdma | tcp,rdma]] NEW-BRICK... |

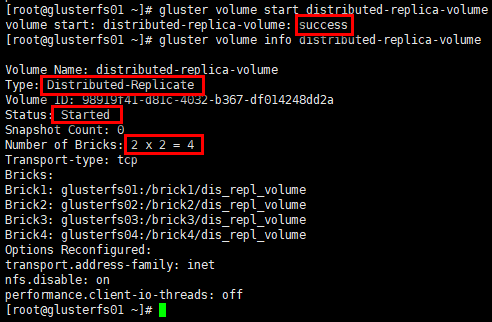
启动卷
1 | # 卷类型:分布式复制卷 |
client挂载
1 | [root@glusterfs-client ~]# mkdir /mnt/distributed-replica |
查看挂载情况
1 | # 已挂载卷的容量是2个副本集(replicated sets )容量之和 |
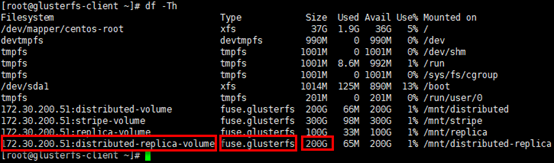
存储测试
1 | # 在client的挂载目录下创建若干文件 |
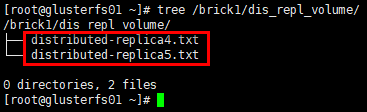
1 | # glusterfs02节点 |
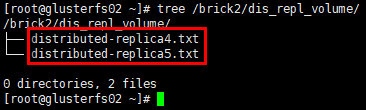
1 | # glusterfs03节点 |
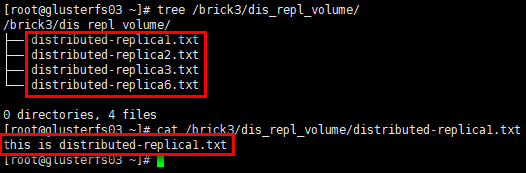
1 | # glusterfs04节点 |
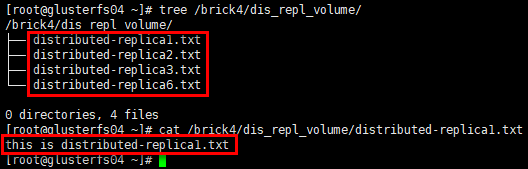
结论:分布式复制卷将数据文件分布在多个复制集(replicated sets )中,每个复制集中数据有镜像冗余。
分布式条带卷(Deprecated)
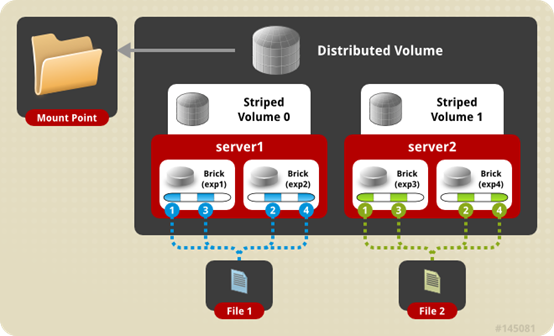
分布式条带卷(Distributed Striped Glusterfs Volume),是分布式卷与条带卷的组合,兼具两者的功能,特点如下:
- 若干brick组成1个条带卷,另外若干brick组成其他条带卷;单个文件在条带卷内数据以条带的形式存储,不同文件在不同条带卷之间进行哈希分布;即分布式卷跨条带卷;
- brick server数量是条带数的倍数,且>=2倍,即最少需要4台brick server。
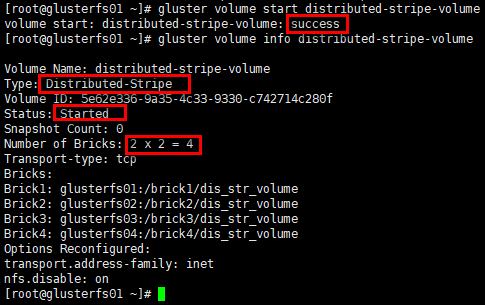
创建分布式条带卷
1 | # 命令:gluster volume create NEW-VOLNAME [stripe COUNT] [transport [tcp | rdma | tcp,rdma]] NEW-BRICK... |

启动卷
1 | # 卷类型:分布式条带卷 |
client挂载
1 | [root@glusterfs-client ~]# mkdir /mnt/distributed-stripe |
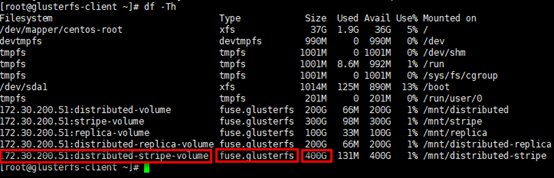
查看挂载情况
1 | # 已挂载卷的容量是4个brick容量之和 |
存储测试
1 | # 在client的挂载目录下创建若干文件 |
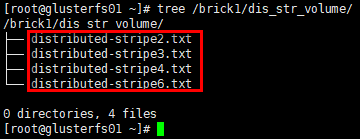
1 | # glusterfs02节点 |
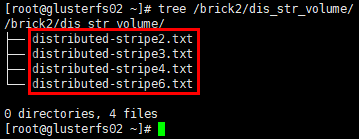
1 | # glusterfs03节点 |
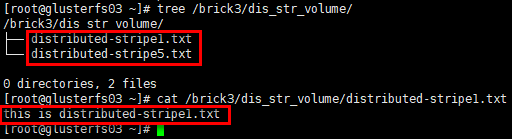
1 | # glusterfs04节点 |
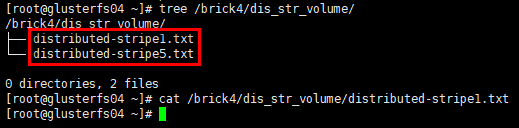
结论:分布式条带卷将数据文件分布在多个条带集中,每个条带集中数据再以条带的形式存储在对应条带集中的全部brick上,数据无冗余备份。
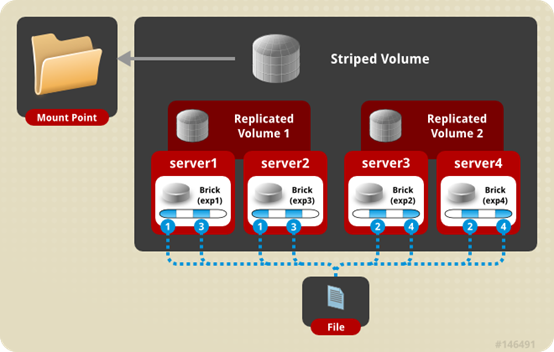
条带镜像卷(Deprecated)
条带复制卷(STRIPE REPLICA Volume),是条带与复制卷的组合,兼具两者的功能,特点如下:
- 若干brick组成1个复制卷,另外若干brick组成其他复制卷;单个文件以条带的形式存储在2个或多个复制集(replicated sets ),复制集内文件分片以副本的形式保存;相当于文件级raid01;
- brick server数量是副本数的倍数,且>=2倍,即最少需要4台brick server。
分布式条带镜像卷(Deprecated)
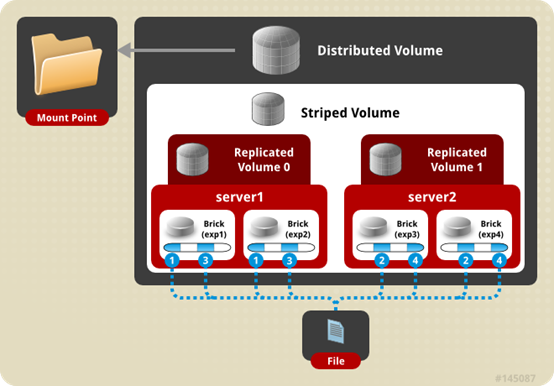
分布式条带复制卷(DISTRIBUTE STRIPE REPLICA VOLUME),是分布式卷,条带与复制卷的组合,兼具三者的功能,特点如下:
- 多个文件哈希分布到到多个条带集中,单个文件在条带集中以条带的形式存储在2个或多个复制集(replicated sets ),复制集内文件分片以副本的形式保存;
- brick server数量是副本数的倍数,且>=2倍,即最少需要4台brick server。
纠删卷
纠删卷(Dispersed Volumes)是v3.6版本后发布的一种volume特点如下:
- 基于纠删码(erasure codes, EC)实现,类似于raid5/6(取决于redundancy等级);
- 通过配置redundancy(冗余)级别提高可靠性,在保证较高的可靠性同时,可以提升物理存储空间的利用率;
- 文件被分割成大小相同的chunk(块),每个chunk又被分割成fragment,冗余信息的fragment随之生成,且同一个fragment只会保存一个brick上;
- redundancy均匀分布存储在所有的brick,逻辑卷的有效空间是
= * (#bricks - redundancy); - 在数据恢复时,只要(#bricks - redundancy)个fragment(数据或冗余信息)可用,就能正常恢复数据;
- 卷中所有brick容量需要相同,否则最小的brick满容量时,数据无法写入;
- 实际部署时,redundancy < #bricks / 2 (or equivalently, redundancy * 2 < #bricks),即brick至少是3个;redundancy设置为0时,DispersedVolume等同于分布式卷;若redundancy设置为brick/2时,DispersedVolume等同于复制卷。
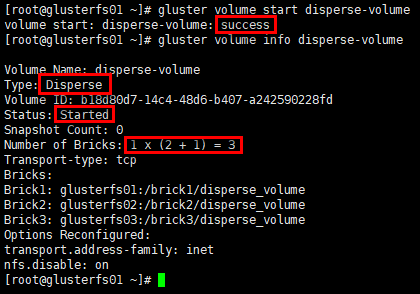
创建纠删卷
1 | # 命令:gluster volume create [disperse [<count>]] [redundancy <count>] [transport tcp | rdma | tcp,rdma] |

启动卷
1 | # 卷类型:disperse卷 |
client挂载
1 | [root@glusterfs-client ~]# mkdir /mnt/disperse |
查看挂载情况
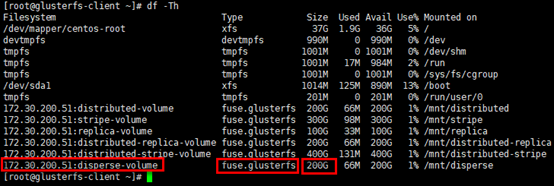
1 | # 已挂载卷的容量是2个brick容量之和,<usable size> = <brick size> * (#bricks - redundancy) |
存储测试
1 | # 在client的挂载目录下创建若干文件 |
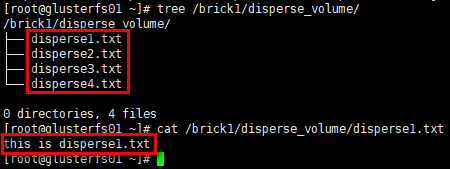
1 | # glusterfs02节点 |
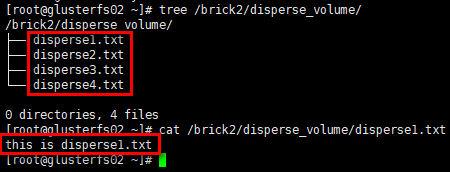
1 | # glusterfs03节点 |
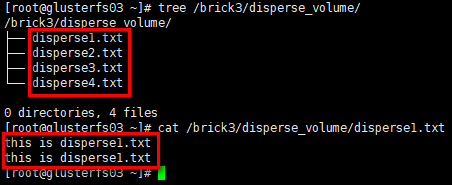
结论:纠删卷将数据文件(含冗余信息)分布在多个brick中,数据有冗余。
分布式纠删卷
分布式纠删卷(Distributed Dispersed Volumes)等效于分布式复制卷,但使用的是纠删子卷,而非复制子卷。
Glusterfs管理
均衡卷
1 | # 不迁移数据 |
删除卷
1 | # 删除卷操作,必须先停用卷; |
brick管理
1 | # 添加brick |
日志
相关日志,在/var/log/glusterfs/目录下,可根据需要查看;
如/var/log/glusterfs/brick/下是各brick创建的日志;
如/var/log/glusterfs/cmd_history.log是命令执行记录日志;
如/var/log/glusterfs/glusterd.log是glusterd守护进程日志。

